Spiderfoot is an amazing tool that automates data collection by querying almost every place in the world wide web. You can learn about it here: https://github.com/smicallef/spiderfoot . But I wanted to free the spider and allow it to see beyond its web. (sorry for the joke, ChatGPT wrote it). More percisely I have a lot of local datasets, which I use for OSINT investigations and was a bit sad that Spiderfoot could not access them, because they contain some nice info. So I went ahead and wrote a simple plugin that gives Spiderfoot access to local data. In this article I will show you how it was done, so you can implement it in your own workflow and modify it, if needed.
Installation
But before we do this, let’s talk about how you can use it. The modules Github repository is located here: https://github.com/her0marodeur/Spiderfoot-local-data-module .Obviously you have to install Spiderfoot, instructions can be found here: https://github.com/smicallef/spiderfoot#installing--running. It is not officially included in Spiderfoot, because it is a very niche use case and it could potentially confuse users. That means you have to import it yourself. The importing of the module is as easy as just copying it to the modules directory of your Spiderfoot installation and (re)starting your Spiderfoot server.
Usage
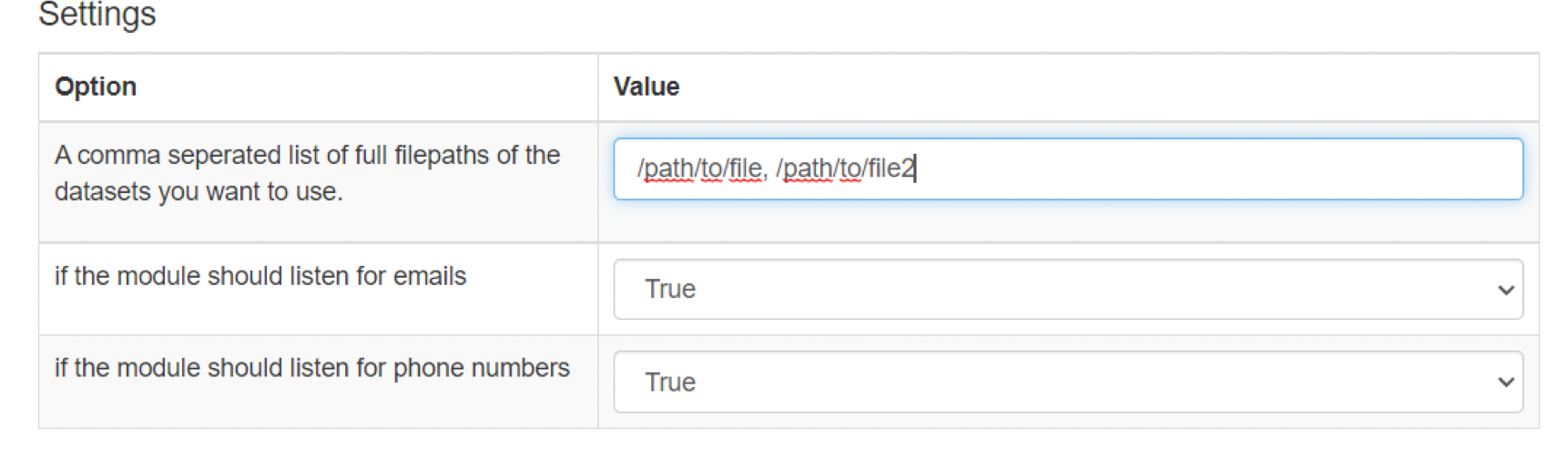
Datasets have to be stored on the local machine. If you want to make them available for Spiderfoot, you have to include their full path in the settings of the module. Multiple files can be specified in a comma separated list. Below the path configuration you can select what kinds of data the module should listen for. So, if that kind of data is found during your scan, the module will automatically start searching for it in your local files. Do not forget to click “Save Changes”.
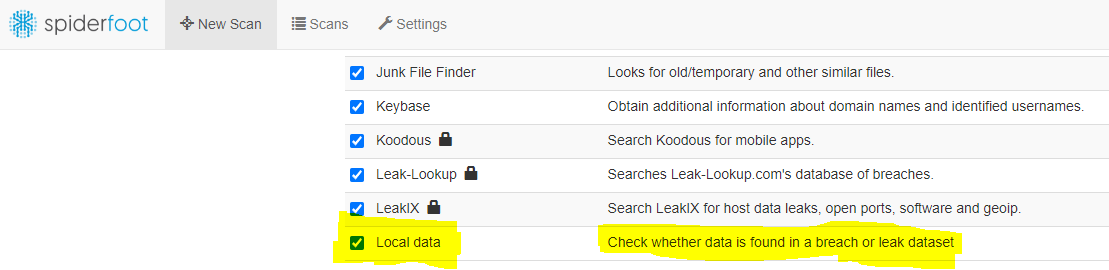
Afterwards you can select the module in the scan settings in the “By Module” tab.
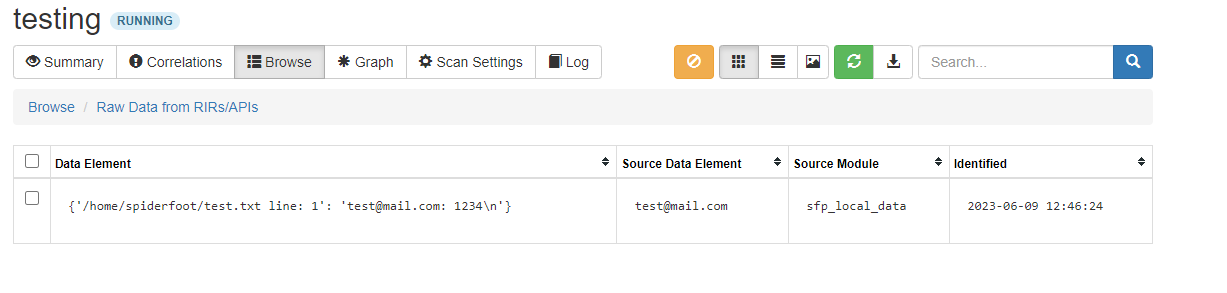
If the scan finds anything in your local dataset, it will report the filename, line and content back as “Raw Data from RiRs/APIs”.
This implementation was able to search a 30GB file in 3 minutes, which will slow the search process down, if a lot of data is present. Possible speed improvements could be done by implementing ripgrep, but this would require additional libraries. If you have any improvements, I am looking forward to your Pull Requests on Github.
Changing the module
Spiderfoots modular design allows you to easily extend it with a little bit of Python code. This ability makes it amazing and you can learn about it here: https://intel471.com/attack-surface-documentation#writing-a-module .
The local data Spiderfoot module allows a user to let Spiderfoot query local datasets, mainly leaks and breaches, but it could be extended to other local datasets as well. It works with the native Python ability to read files as seen in the following code block:
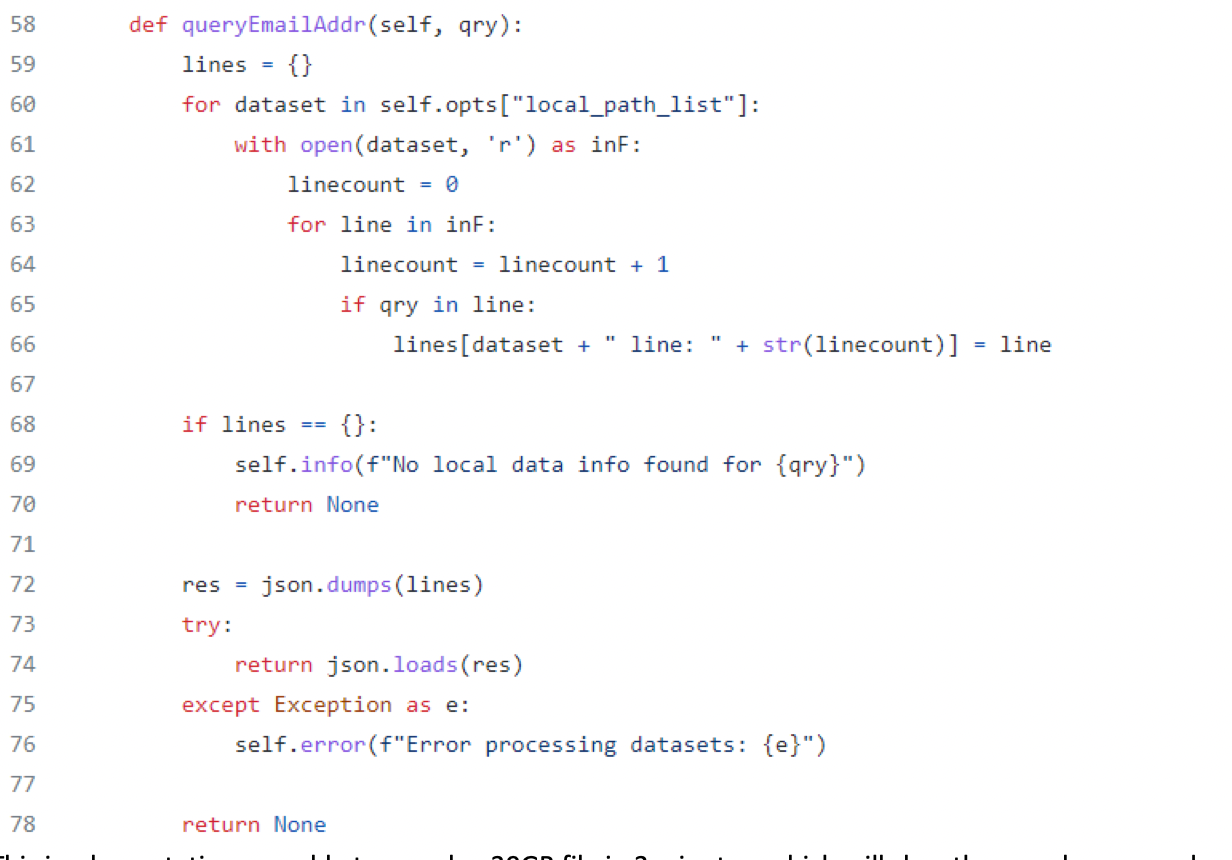
In the configuration of the module, you can select to types of data to listen for. For now I have only implemented email and phone number, but it is easily possible to include many more. If you have other data in your local dataset, just add it to the options list and in this if statement.
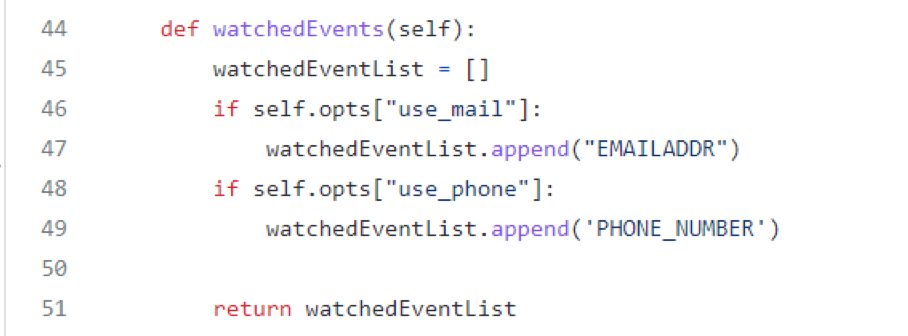
The module is coded in a very flexible way, so it will be useful for many use cases. It is easily extensible and can also serve as a template for people looking to implement similar use cases.
If you enjoyed this article, you can check out my other stuff at: https://security-by-accident.com/ or follow me on Twitter @secbyaccident.